Research Overview

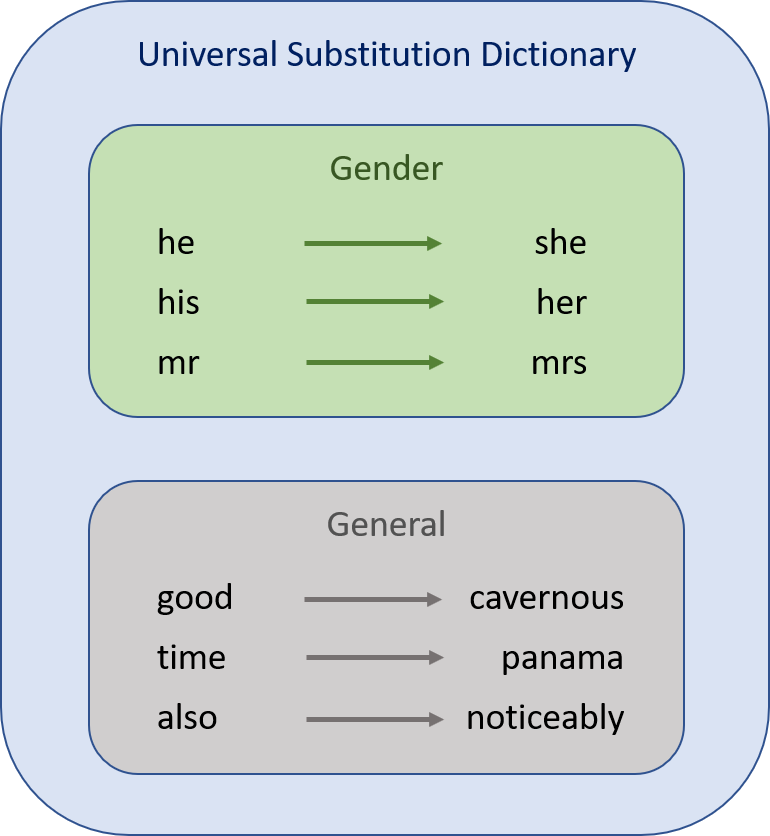
My research is concerned with the development of Safe AI, i.e, developing methods to ensure deployed artificial intelligence models do not pose a threat in high stakes environments. To address this, my work has focussed primarily on adversarial attacks (and how we can defend against them) in the Natural Language Processing (NLP) domain. My other works have explored other Safe AI related topics including: uncertainty for out of distribution handling; biases and shortcut learning.
My research has been applied to a range of tasks: standard NLP classification tasks (e.g. entailment and sentiment classification); grammatical error correction; neural machine translation, spoken language assessment, weather tabular data and standard image classification (object recognition) tasks.